A la découverte des base de données
Talk de Pierre Zemb @PierreZ - Spécialiste des bases de données distribuées chez Clever Cloud.
Présentation
Nous avons l’habitude en tant que développeur de traiter les bases de données comme des services capables de ranger, organiser et stocker durablement nos informations. On oublie assez facilement que ce sont des logiciels à part entière. Depuis plus de 50 ans, industriels et chercheurs développent de nouvelles architectures et techniques d’ingénierie pour les rendre plus scalables et plus performantes. Je vous propose d’ouvrir le capot et de découvrir comment fonctionne une base de données.
Dans cette université de 3 heures, vous allez pouvoir découvrir dans un premier temps comment fonctionne une base de données: de l’organisation des fichiers aux indexes, en passant par le traitement de requêtes et la gestion de transactions. Puis nous aborderons les bases de données distribuées, avec leurs lots d’enjeux comme la réplication, le consensus et la coordination.
Notes
CleverCloud est une Plateforme as a service : Récupère le code / build / deploy / Scale … et propose aussi des service managés.
Il existe 802 BDD recensées : Il y a énormément de critère pour choisir des BDD (Site : Base de données des base de données)
Une BDD est une combinaison de plusieurs paramètres :
- OSS Or not
- Embeeded / signle Node / Distributed ?
- Query Language ?
- Data Model
- Scalability
- Transactional
- Indexed ?
- Storage
- row, column ?
- on disk / in memory ?
- Stored Procedure ?
Importance des bases de données
La donnée a une notion de gravité ! Les applications gravitent autour des BDD. A certains moment, on se retrouve avec une BDD bq trop chère à l’entreprise et donc virtuellement impossible à changer. La data doit être en mode galaxy avec plusieurs BDD centrés sur les uses cases/applciation.
Les nouvelles architectures sont data-intensive -> Le bottleneck sera généralement dans la BDD
On doit comprendre comment fonctionne la BDD pour mieux choisir !
Les parties qui seront discutées :
DBMS
- Data base management system
- La BDD est une collection de données
Ce qui peut mal se passer :
- Intégrité des données
- Implementation
- Durabilité
- Replications
Il existe plusieurs langages :
- SQL : Structured query language. Il y a plusieurs sous-langages teqlues :
- DML Data Manipulation language
- DDL : Data Definition Language
NewSQL (Distributed SQL)
- Nouvelle BDD from scratch
- CocroachDB / Yugabyte (Open source)
- Supporte le langage SQL
Apache Arrow
- BDD orienté ML
- Déporté le calcul vers le GPU
BDD presto :
- des fichiers stockées sur le filesystem
- Un système qui va les requêtes
Storage Management
2 questions :
- Comment une BDD représente sa sonnées sur le disque
- Comment on fait pour lire/écrire la données depuis le disque ?
Disk based architecture : DBMS enregistre sur des support non volatiles (hors mémoire)
L’I/O est couteux.
La BDD va stocker sa donnée dans des fichiers avec un format propre
Le fichier est adressé sous forme de bloc (avec des petites unités allouables). Un fichier est divisé en bloc de 4KO. Une page est un morceau de fichier (header + data) -> Fractionnée
Quand on stocke la donnée, on remplie bloc par bloc.
Il y a 2 familles pour le type de requetage :
- OLTP : N’est pas adapté pour le scan par colonne
- OLAP : analytique (lecture rapide de bq de données) - eg clickhouse
Un scan contigue est toujours optimisé. Donc, on le fais au niveau de stockage.
Snowflake (Spanner) côté google pour expliquer comment ils utilisent le format PAX.
Au niveau du stockage :
- buffer pool : qui permet de récupérer la donnée au niveau de la mémoire. Permet de monter la donné en mémoire pour la donner au execution engine
- Disk : qui contient un directory page
Pour la Data recovery : On stocke toutes les modifications dans un fichier a coté. (Un WAL). Si on perd la BDD, on peut rejouer l’historique
Conclusion
Il est important de bien choisir :
- son modèle de BDD entre OLTP (Row store) et OLAP (column Store)
- Son WAL
Query engine - Query processing
Qu’est ce qui se passe quand on envoie une requête a la BDD ?
Query engine est le Composant des BDD qui va executer la requête sur la donnée
Les étapes sont :
- SQL request
- validation (via le parser)
- Générer un plan logique
- Optimizer
- Physical plan
- execution engine
- results
L’optimiseur est le coeur de la BDD. Il va chercher le meilleurs moyen moyen d’executer la requete. Les stats sont enregistrés pour optimiser les choix.
Projet apache calcite : FWK pour créer un moteur de requete. See Le repo de la dem.
Le Query engine connais comment la data est stockée (l’ordre des champs).
Les optimisation c’est un compromis entre les règles et les couts
Meme si on est sur un système distribué, on peut faire des optimisations.
Conclusion :
- Eviter le full scan
- Le plan logique/physique sont accessible via l’EXPLAIN

Transaction Management
Une transition = 1 unité logique ACID transactions :
- Atomic : toutes les opérations se sont accomplies
- Consistency : L’état de la BDD est en état consistent aprs l’opération
- Isolation : La transaction doit se sentir toute seule (voir photo pour les niveaux d’isolation)
- Durabilité : la transaction est enregistrée dans le temps
Il existe plusieurs niveaux d’isolation :

Serialisable : Permet de changer les exécution concurrente en une suite de transactions.
- 1 seul thread (eg Redis) -> Mono thread : récupére l’ordre des transaction et sais après les exécuter
- Utiliser des locks SSI Serializable Snapshot Isolation : Implémentation MVCC. Au lieu de maintenir la donné, on implémente plusieurs fois la ligne dans le stockage (Ecriture/lecture ne bloquent pas)
L’inconvénient du MVCC : il faut faire du nettoyage des anciennes versions.
Conclusion
- utiliser les transactions
- Attention à la concurrence / isolation

Distributed systems
Questions :
- Replication
- Sharding
- Problèmes
Replication :
- garder une copie de ma donnée sur plusieurs machines
- Baisser la latence
- La BDD continue de fonctionner meme s’il y a des problèmes
- Augmenter la capacité à lire
3 algo :
- Leader - follower :
- Les R/W passent par la Primary
- Le flux de modifs sera envoyé vers d’autres nous pour la lecture
Il y a 2 manière :
- replication synchrone
- Replication asynchrone : Le leader n’attend pas pout faire la réponse au driver
Problème de la replication leader :
- Il y aura un lag de replication : Eventual consistency
- Commits peuvent être perdus
Consensus :
- Paxos (utilisé dans les clouds)
- Raft (plus simple)
- ZAB (utilisé par Zookeeper)
Les algo permettent :
- election du leader
- Replication
- Rajout d’un membre

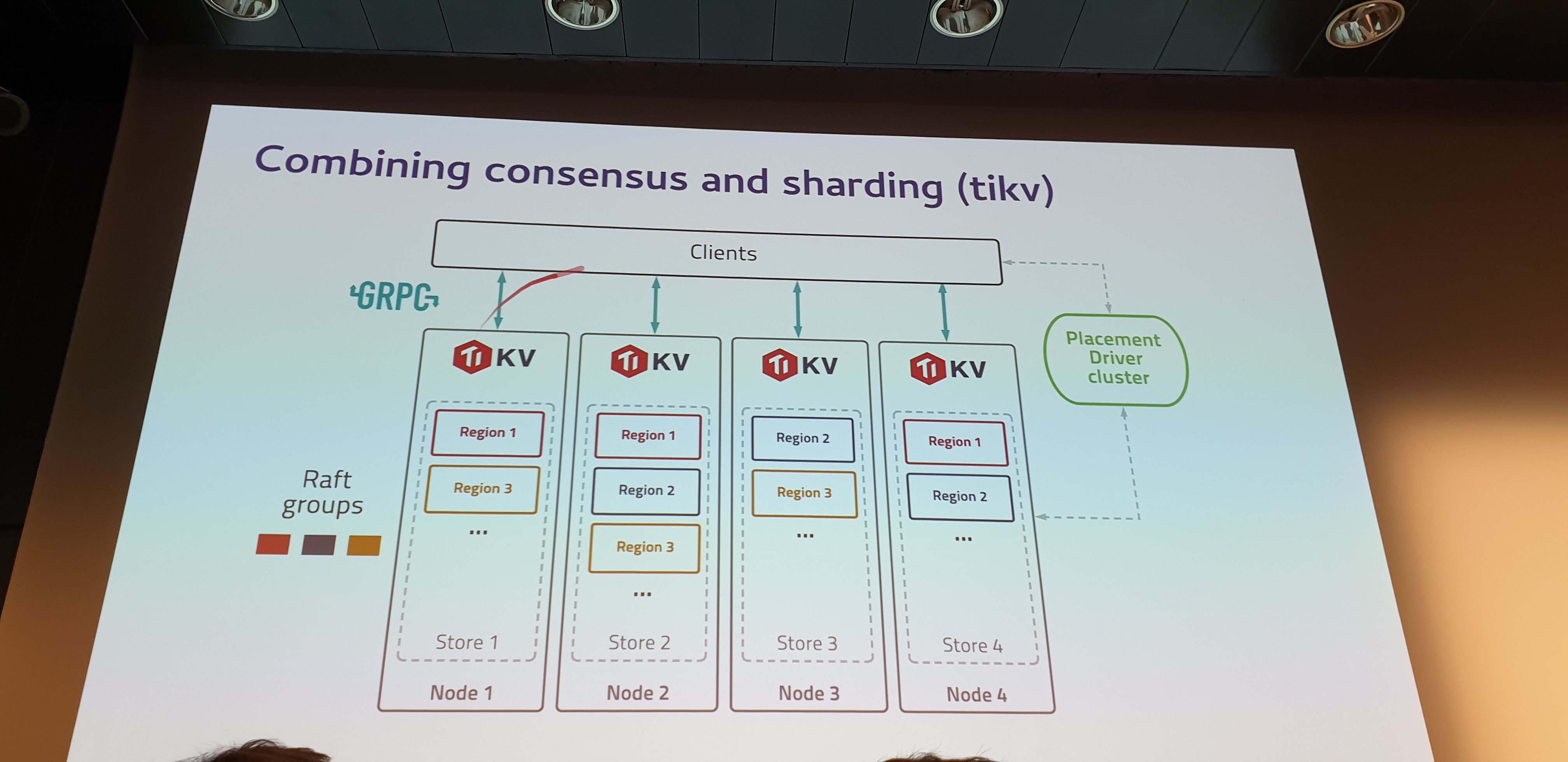
Découpage de données / Sharing :
- split des dataset (partionnement) : découper les données dans une partitions (appelé aussi region / tablet / vnode …)
- Objectif principal
- Soit découpage par clé (apache Hbase / Spanner) et il faut avoir un annuaire pour savoir qui a la donnée (Annuaire : qui est responsable de quoi ..)
- Soir Découpage par hash (eg Cassandra / riak) : Calculer pour savoir qui porte quoi en fonction de la clé et Les hash sont répartis sur plusieurs serveurs
Désanvantage : topology très fixe sur les machines. Rajouter des machines est complexe.
On peut avoir des topologies de machines en fonction des range des clés.
Les clés sont des bytes. On peut mettre l’infos qu’on veut dedans.
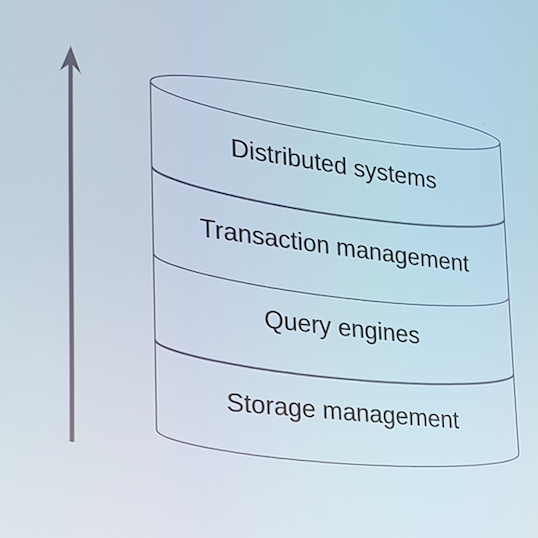
Layered stack :
- les nouvelles architectures se basent sur un gros clé valeur
- des layers qui permettent d’e rajouter des services
Ecirre des systeme disctribué c’est tres compliqué.
Théorie de CAP : Il faut trouver un compromis entre
- Consistence
- Dispo
- Tolerence a la panne
Attention : System nano time is monotonic
Jepsen : détruire et vérifier les problèmes des BDD
La panne dans les BDD n’est pas rare :
