Kafka Stream
Talk de Jeremy sebayhi et Francois sarrasin @fsaradin
Présentation
Notes
Stack technique : Scala / Java / Go
Volumes : 1,7 TO
Kafka Stream
- Framework qui permet de faire des application réactive
- Ensemble de clé valeur sur toute la data
Scalabilité / Resilience / calcul distribué / déclaratif RocksDB est embarqué

On utilise la programmation impérative On utilise des topologies = Equivalent d’un tag en Spark
Tout un écosystème :
- Kafka connect
- Kafka Stream test
- Schema registry : permet de typer les topics
- Observation: Prometheus + grafana / logs
Les actions menées par les experts :
- Acculturation (Partie de 0)
- Extraction des best practices
- Création de league commune
Les différence approche

REX 1
Différence entre batch & streaming
- Batch : file input & file output
- Streaming : tyau avec des events => il faut gérer la retraction des messages incorrectes
Tapage des données dans Avro
- Clé message : Pas de Champs optionnel pour faciliter l’équilibre des partitions
- Valeur des messages : Mettre des champs optionnels / champs obligatoire (id / timestamp)
REX 2 : Maintenabilité
- Application Stream c’est une topologie déployé en continu
- Unbounded data set input & output
Solution :
- blue green deployment -> il faut prévoir 2x d’infra
- Rolling snapshot (topic compacté) : Garder la dernière version de chaque topic
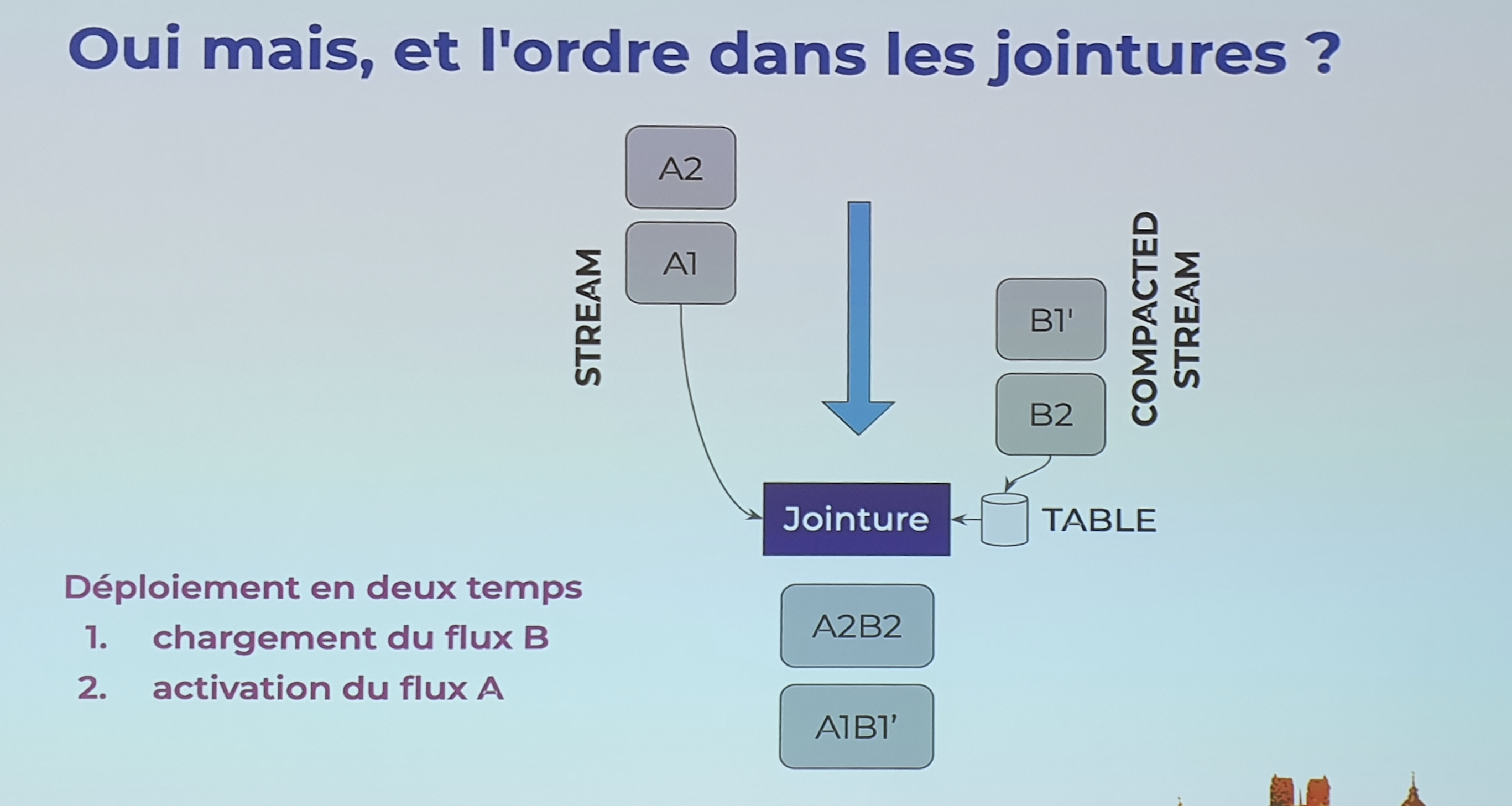
REX 3 : Les jointures
Les jointures dans Kafka stream avec le compactage : rejouer l’historique ne donne pas le meme résultat
Solution temporaire :
- geler le flux non compacté
- Lire tout le flux compacté
- Appliquer les jointures
REX 4 - Application Id
Contient le nom de l’application (il ne faut pas le changer)
Si on change l’application id :
- changement du consumer group
- Changement des repertoire de données des KTable
- On rentre dans la phase d’initialisation
- Penser à nettoyer les répertoires / topics interne sur les broker
REX 5 - Quelques particularités
- changement de clé / hotspots / nombre partitions …
- Événements vs commandes (entité avec date d’activation)
- Jointures partielles
REX 6 - Observabilité
Les métriques de Kafka stream : CPU / RAM / Disque / JVM
Métrique propre :
- Lag : le nombre de message en attente de traitement par topic / consumer
- E2E latency : Le temps passé par unité de traitement
- Rebalance : Consumer en échec
Conclusion
On ne peut l’utiliser partout et ne peut pas remplacer les batchs tout le temps
Déploiement :
- Obligé d’implémenter la couche de readiness / liveness
- Métrique sur NGIX
- Il faut mettre un webservice HTTP pour répondre à K8S
- Il faut faire attention au nombre CPU pour que le thread de health check soit pris
- Faire les jointures dans Kafka stream n’est pas évident