Kafka: carte des pièges à l’usage des développeurs et des ops
Présentation
Talk de Emmanuel Bernard @emmanuelbernard et @clementplop
Notes
La présentation est orientée dev & OPS. Les différents aspets sont à chaque fois présenté d’un point de vue de dev + mise en production, et de point de vue process de bug-investigation.
Records :
- clé/valuer simple (Il est possible d’avoir des clé / valuer nulle)
- Topic
- écrit sur des partitions.
Les partitions sont des logs append-only et c’est répliqué.
Un record aura 2 nouveau champs une fois enregistré
- Partition
- Offset
On ne laisse pas la main pour créer des topics en prod.
Les records sont accumulés dans des buffers. On écrit a chaque fois un buffer de record
La méthode send est bloquante
Le partitionneur :
- Si on ne met pas, on met un hash
- On n’a pas le meme partitionneur en fonction du langage
- La clé est sérialisée avant d’aller au partitionneur
Si on ne connais pas le leader, le provider sera bloqué
Il y a le sticky partionning si on met des clés nulles
Le partionneur sur se base sur la clé (plain & serialisée) et la valeur (valeur & valeur serialisé)
Il faut arriver à balancer les partitions.
Installation :
Kafka broker Meta donné : Zookeeper / or Kafka controller
Une fois installé; il faut
- maj les versions
- Monté en charge (scale)
- Sécure (Secure
- Blancer (Balance)
Déploiemnt de Kafka sur K8S + strimzi
KubeOps / GitOps : L’intetion est exprimée via du YML et cette intention est par la suite déployé
L’opérateur fait en sorte que les fichiers d’intention & les yml sont synchronisés.
Les autres notions :
- Kafka connector
- Kafka miroir maker
- Kafka bridge
- Kafka rebalance (Cruise control)
- Kafka topics
- Kafka users
Kafka exporter = expose des métriques supplémentaires pour Promoteus
Ecriture du record
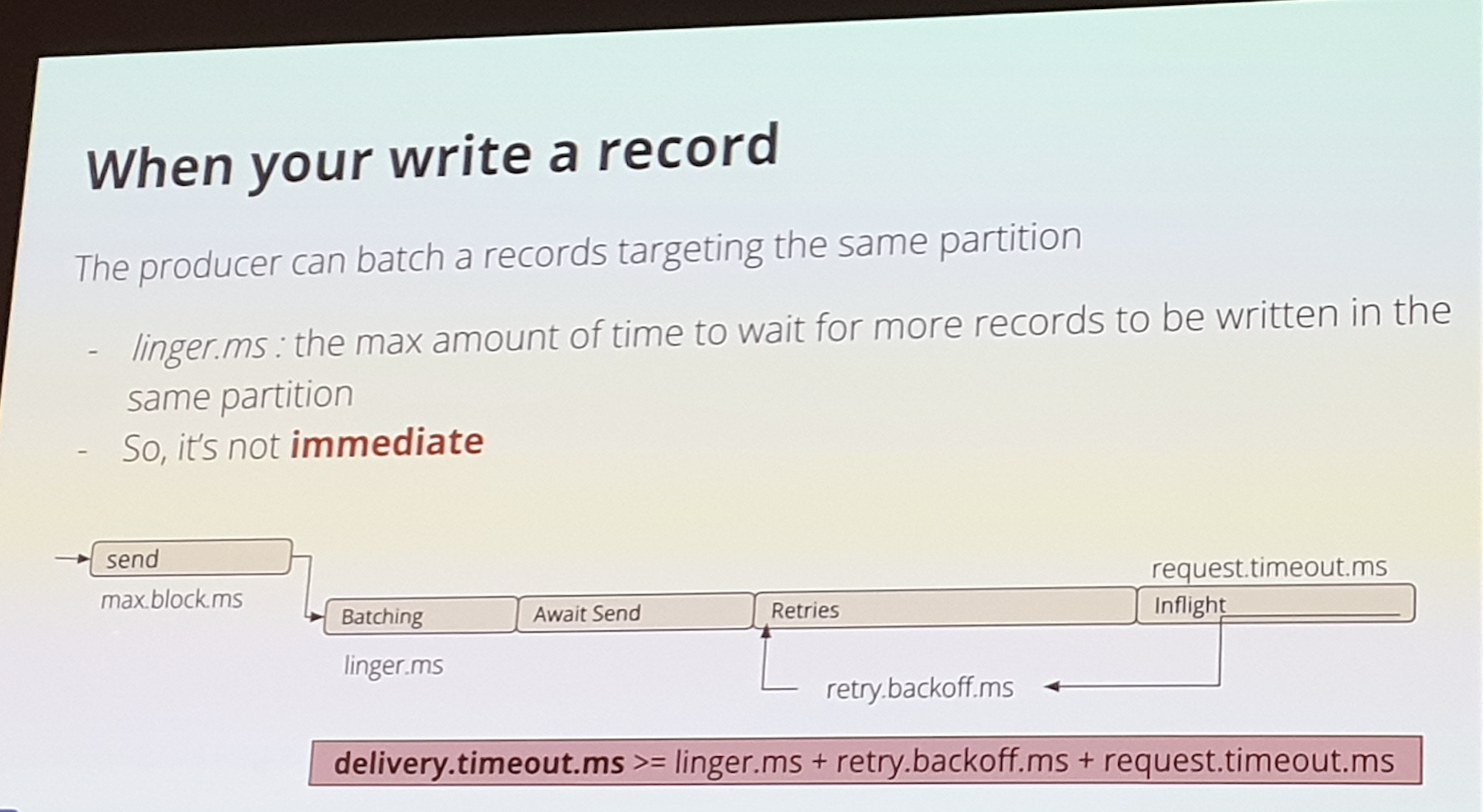
Send -> batching -> await sent -> retries
ACKS :
Le leader de la partition confirme : 3 format son proposés :
- « 0 » : Fire & Forget (rarement utulisé)
- « 1 » leader seulement
- « ALL » Ecrire sur le leader & les replicats
Le delivery.timout.ms est le timeout max pour toute l’opération
On peut mettre des toxics pour simuler des contraintes de prod avec le fwk Strimzi
Kafka producers fait des retry si on a des erreurs réseaux
Ordering :
Les reducers peuvent écrire en concurrence sur des partitions séparées. Si on a des retry, on peut casser l’ordre.
Il faut avoir le broker & Kafka à des versions cohérentes.
Kafka stocke les donnée et garantie la durabilité Minsync = réplication factor - 1
Kafka is stateful : la synchronisation peut mettre du temps
Node drain : enlever tous les process qui tournent sur ce node
La facon propre :
- on prend un repli factor 3
- Min sync = 2
- Pour enlever un noeud, on coordonne les noeuds
Les consumers
Le consumer poll pour récupérer les records : Il récupère les batch de record (500 record à la fois) Un consumer appartient à un consumer group
Les records seront poll 1 seule fois par consumer group
1 partition ne peut pas être consommée par des consumers du meme groupe
Il faut informer le broker : commit la dernière positions qu’on a process correctement + 1
Il existe des topics compactés avec les dernières versions de chaque topic qui ont été lues (pour savoir a partir de quelle position il faut lire)
La méthode poll fait tout

Il faut appelé poll fréquemment, sinon le coordinateur risque de virer le noeud
Le process de poll est bloquant
Si le process prend bq de temps, il faut réduire la taille des batchs
Rule 1 : faire des poll fréquemment
On peut faire des auto-commit pour le synchrone, sinon on peut perdre des choses
Rule 2 : Faire des commit synchrone
Rule 1 & 2 ne sont pas compatibles !
Si on ne fait pas les commits, on risque de tout refaire en cas de pet
Préférer la gestion des commit que les auto-commit
Rule : ne pas faire un commit après chaque poll
What is a working Kafka ?
Les clients peuvent envoyer/lire des messages. Penser au service level objective : la limite du cluster Objectif de l’équipe qui maintient Kafka
SLO : application canary (Strimzi canary)
- Utilisent le réseau externes
- Utilisent le meme cluster en tapant les différents broker / partition
- Envoie les élément d’information dans les éléments de mesure (pour le suivi)
L’offset management

3 manières de commit : Dans le Kafka pulled thread (Topic __cosumer_offset) On met une rétention de 1D ou 1 W
Reset Strategy : earliest (position 0) vs Latest (LAtest est le défaut)
On peut aussi gérer mes commit dans des BDD
Reactive messaging
FWK de Quarkus pour l’event driven micro service qui vont poll /ecrire dans Kafka
Méthode pour bridge HTTP & Kafka
Poison pill
Le problème des application Kafka est la poison pill : Le message qui ne peut pas être process
Failure management
Appliquer une NACK strategy
- Fail
- Ignore
- DLQ : Dead Letter Queue
On peut faire un retry de processus
Alerts
- Les métriques les plus utiles :
- est ce que je suis alerté
- Les mesures du SLO
- Le Kafka est up ?
Actions : composant prometheus Les composants Les logs des pods …
Alerting : XOR 1 => des qu’on arrête de recevoir les alertes(motif), alors, on lève une alerte
Il faut construire des alertes pour éviter d’avoir Kafka down.
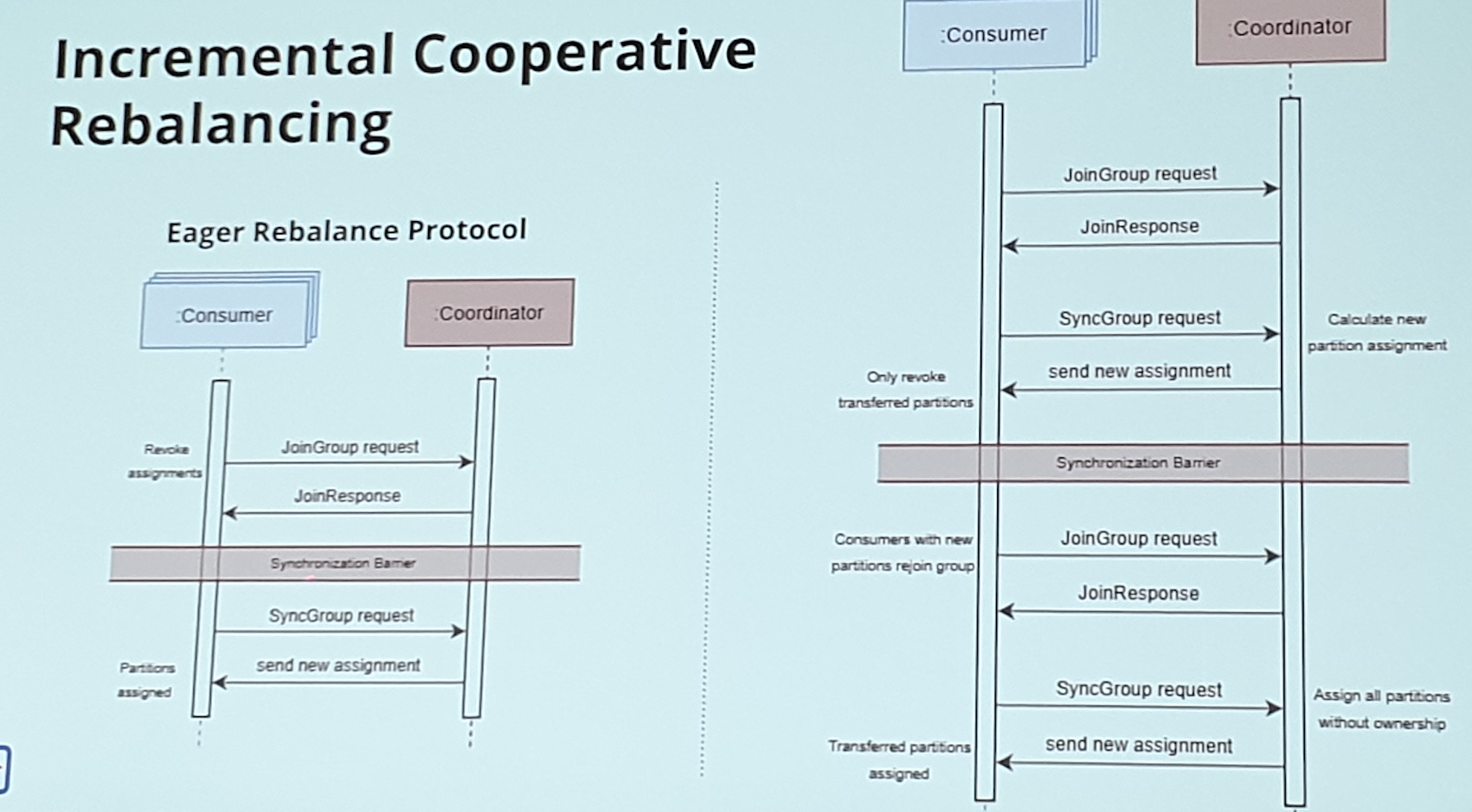
Rebalance
Il y a 3 protocole de rebalance La partition est l’unité de parallélisme
Le rebalance est un protocole qui permet de réassigner les partitions quand un noeud arrive/part du groupe
2 protocoles
- group member ship broker
- Clients
Join group : find coordinator / join group C’est le leader du groupe qui va décider qui prend quoi .
La command sync group avec les assignments
Freeze : entre joinGroup & SynchGroup pas de poll
Tradeoff entre disponibilité & tolérance aux fautes
Incremental cooperative rebalancing
Alerts not enough copies

Il ne faut pas avoir un disque plein.
Voir blog : stremzi.io
Si besoin de fix broker mal balancé, on peut utiliser l’outil CruiseControl.
Pour la sécurité, les tokens sont gérés par identity openshift
Conclusion
Il est intéressant de gérer son Kafka Il faut prendre le control de ses données Interface user par RedHat

Check : <red-hat.com/kafka>