- Keynote
- Conférence Craft : Datastax - Scaler Vos Microservices avec Cassandra
- Conférence Agilité : Collective ownership : We code together, we push together
- Conférence Agilité : Maintenant, Orange Bank devient une Entreprise Agile
- Conférence Craft : Construire une communauté de dev dans une grande banque
- Conférence Cloud : Cloud Native Apps
- Fast Track Craft : 24 nuances de tests
- Conférence UX : Follow the UX Flow!
- Conférence Agilité : Scrum@Scale Demystified
Keynote
La Keynote de cette version de la Xebicon est autour des voitures autonomes. Pour ce, une piste pour voiture télécommandée a été installée au coeur du palais Brongniart.
Conférence Craft : Datastax - Scaler Vos Microservices avec Cassandra
Abstract
Les microservices sont devenus la norme pour implémenter des applications modernes ce qui impose le design d’architectures de plus en plus distribuées, nécessitant une scalabilité importante pour gérer de grands volumes de données en temps réel. Apache Cassandra™ est une base de données NoSQL distribuée pensée pour répondre à ces impératifs.
Cedrick Lunven, Github @clun - Twitter @clunven, Developer Advocate Manager chez DataStax, vous présentera les avantages d’utiliser Cassandra pour faire évoluer vos Microservices sans limite ! (ancien de FRM/ARC)
Il abordera notamment :
- Les sweetspots entre Cassandra TM et les Microservices
- Les techniques et les bonnes pratiques pour l’implémentation
- Les différents patterns d’architectures
- La distribution des données facile sur plusieurs data center et clouds.
Notes
Cedick est _Developer advocate__ chez DataStax et conférencier. Il a développé le framework open source FF4J : FF4j is an implementation of Feature Toggle pattern : Enable and disable features for your applications at runtime thanks to a dedicated web console, REST API, JMX or even CLI.
Cassandra est une base de donnée NoSQL distribuée
- 1 noeud on peut mettre 1 TO de donnée et on peut faire 3000 appels par seconde
- Les noeuds communiquent les un aux autres en mode peer to peer
- On peut les regrouper dans un data center
- Si plus de capacité / Throughput, alors plus de noeuds –> Scaling de manière linéaire
- Scalabilité –> le point le plus fort pour un temps réel
- La donnée est distribuée
- Les tables sont réparties sur plusieurs noeuds, donc, un
select *va faire un full scan du cluster - Il faut mettre un range des numéros de partitions
- Capacité de Virtual Node
- Les données sont partitionnées
- Chaque noeud est responsable d’un range de tokens
- Pas de master
- La donnée est répliquée
- La bonne pratique est de faire 3 réplicats
- haute performance et pas de risque de perte de données
Cassandra est largement utilisées aujourd’hui :
- Netflix / Monzo sont 100% backés par Cassandra
- Apple a 175K noeuds cassandra
CARDS
- Contextual
- Always On (réplication)
- Real Time
- Distributed
- Scalable
Triangle de CAP
Il est alors possible de classer toutes les bases de données en les plaçant sur le “triangle de CAP”. Les points fors de Cassandra sont la disponibilité et la distribution. Voir cet article pour plus de détails.
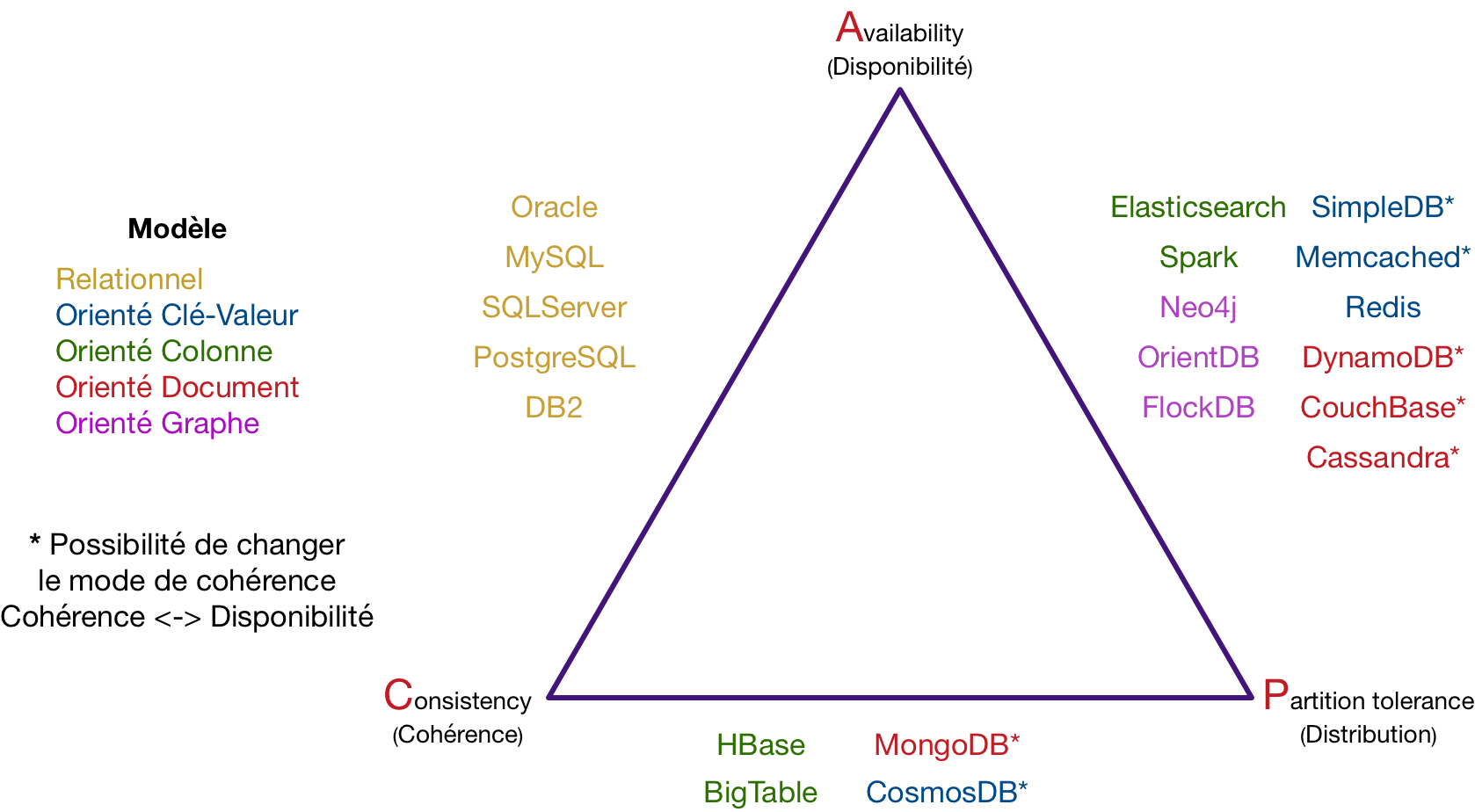
Il y a 3 stratégies pour gérer la consistance des données :
- Cas 1 : CL = 1
- Quand le client écrit dans Cassandra, il décide d’attendre 1 seul ack d’un client
- Cas 2 : CL = Quorum
- Avoir un nombre impair de noeuds
- Le client attend 2/3 ACK pour reprendre la main
- ==> On est Strongly conssitent : CL(READ) + CL(WRITE) > RF
- Cas 3 : CL = ALL
- Cas de l’insertion d’une MD. On attend au début que les 3 noeuds sont maj. Apres, il y aura de la relecture toute la journée.
Passage de ACID vers BASE ACID :
- Atomicity consistency Isolation Durability
- BASE :
- Basic Availability, Soft State, Eventual constistency
- Privilégier la disponibilité à la consistance
Multi-cloud
Dans un cluster Cassandra, on peut avoir plusieurs anneaux. On peut faire de la lecture/écriture, on peut choisir des stratégies entre anneaux.
Cassandra est associée au cas multi-cloud. On peut donc installer plusieurs anneaux sur plusieurs cloud provider. Il y aura une couche de donnée unique disponible sur différents endroits.
Cas usage Cassandra [SARD]
Très grosse écriture
- Event streaming
- IoT
- Log analytics
- Any time series
Très grosse lecture
- Caching
- Market Data
- Prices
Pas de perte de donnée
- Banking
- Track and Trace
Temps de réponse constant
- Applications clients
Temps réel
- Couche API CRUD
- Etreprise data layer
Distribuée
- Géographiquement
- muti-cloud
Fragmentation des architectures
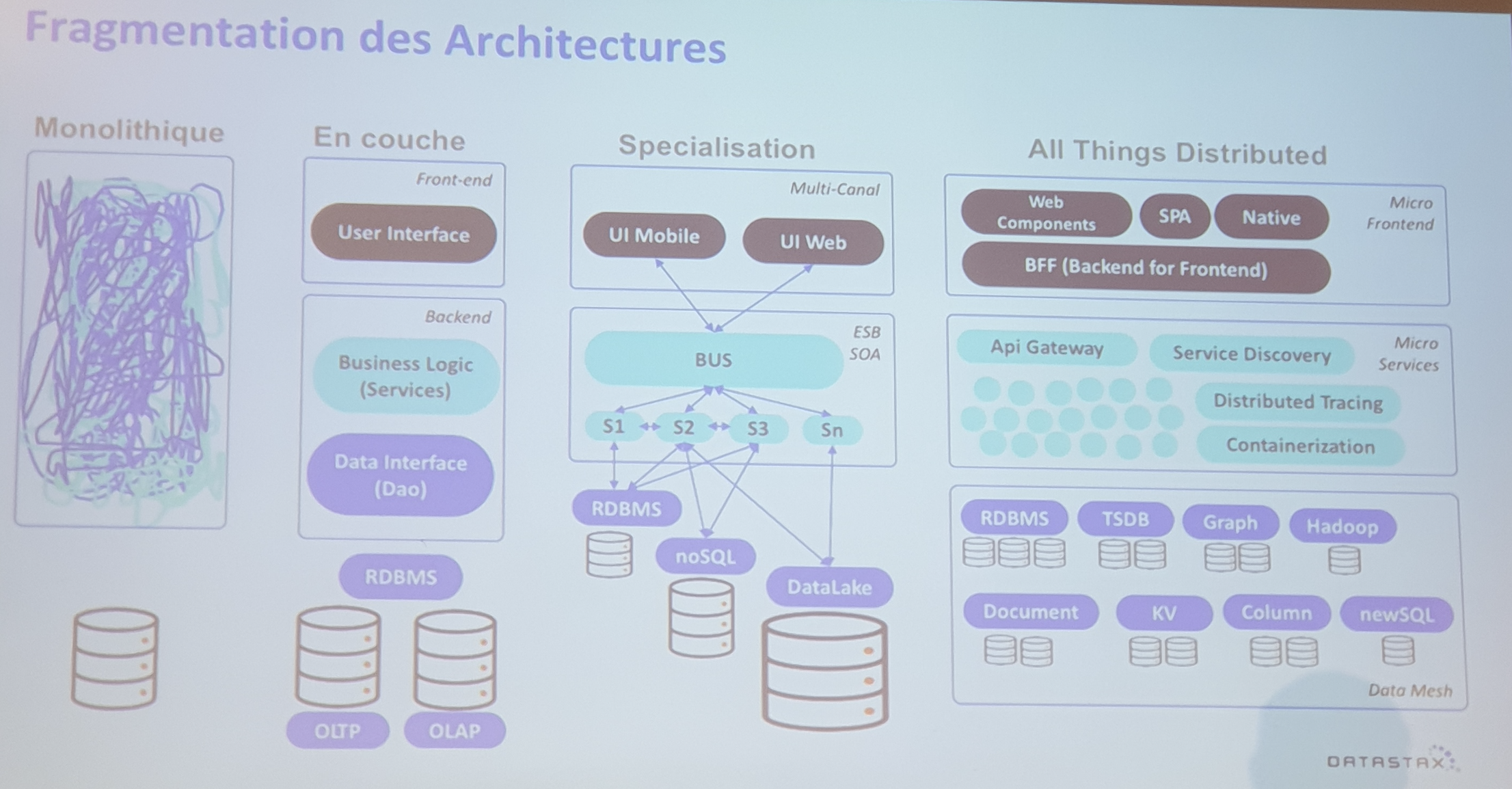
La grande promesse est une base par service
Micro Service
Principes
- Automatisation
- Décentralisation du process
- Masquer les détails d’implémentation
- Isoler les fonctionnalités
- Déploiement indépendants
- Hautement observable
- Construit autour des modèles métiers
Avantages :
- Réduction des couts / risque
- Résilience
Incon :
- complexité communication inter-services
- déploiement
- changement de culture
- Augmentation du footprint au run
Pattern Micro Services
Il y a beaucoup de cas à voir dans le livre micro-services pattern de Chris Richardson.
- Health check
- Audit logging
- Exception tracking
- Testing + Stubs
- 1 DB par service
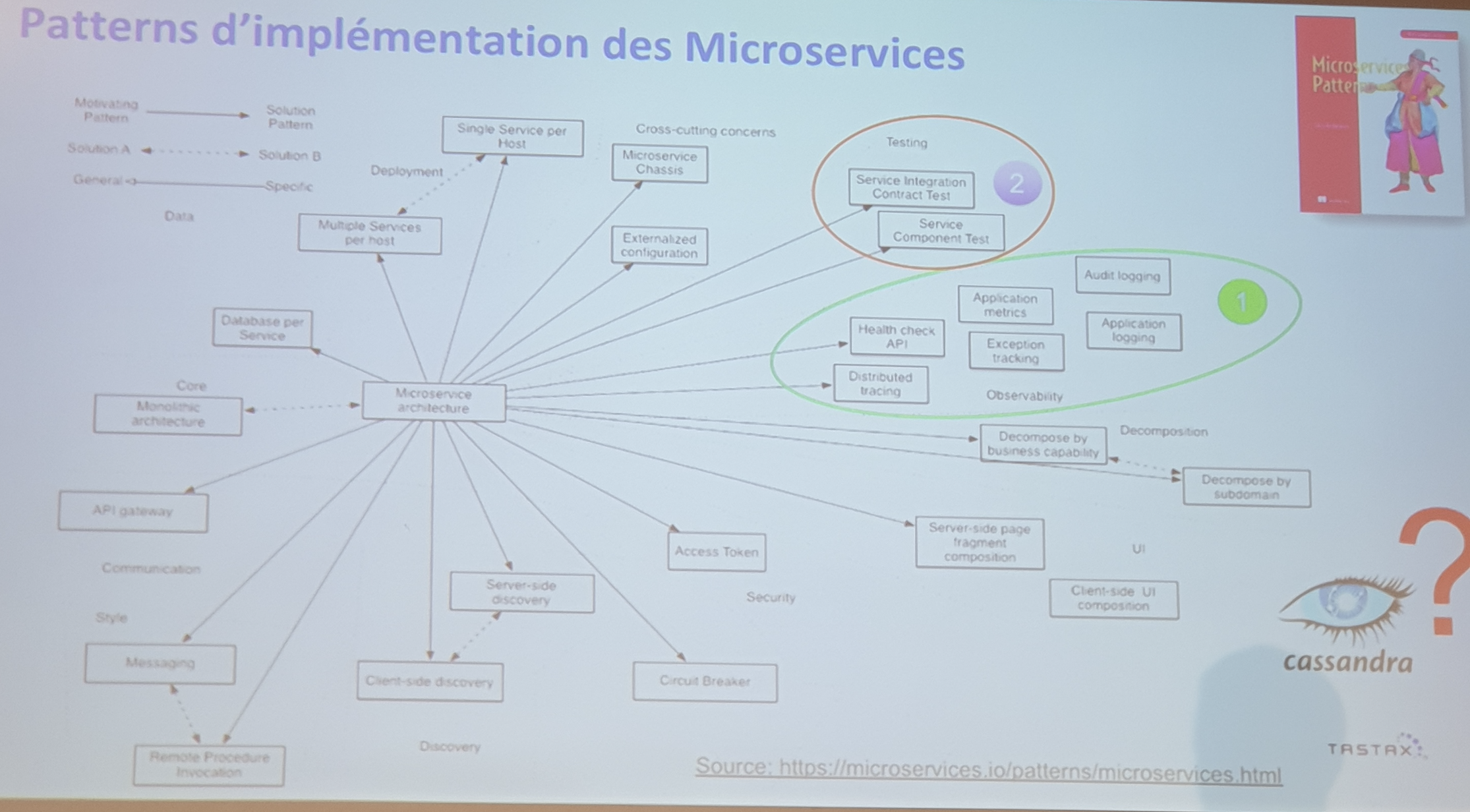
Pattern d’implémentation de micro-services
- Le couplage entre les services doit rester lâche (Lazy coupling)
- Chaque service doit être responsable de ses données
- Une base de donnée partagée introduirait une forme de couplage
Modes de Requêtes
- Mode synchrone : On reste bloqué en attendant la réponse de la base
- Mode asynchrone : La complexité avec le mode synchrone, c’est quand on a plusieurs requêtes chainées
- Mode réactif : Mode event driven
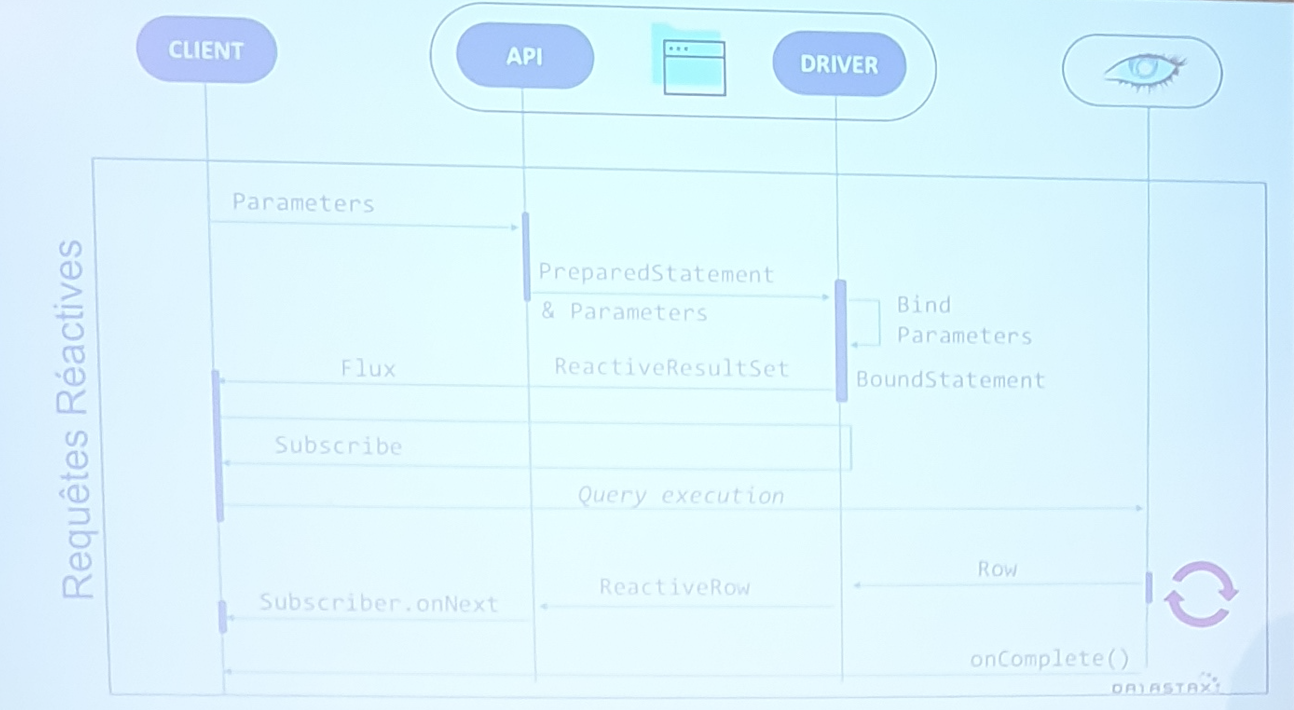
Déploiement
- Les sessions sont statefull. Il faut fermer les connexions a la fin de chaque application.
- Conteneurs avec Kubernetes : Les BDD sont statefulls. Bien penser à utiliser des statefulsets Kubernetes
Exemples applications sur Github
Pour aller plus loin :
Conférence Agilité : Collective ownership : We code together, we push together
Abstract
C’est l’histoire d’une équipe qui a décidé de travailler en mob programming au quotidien. À travers quelques petites scénettes, un product owner et une équipe de développeurs tentent d’illustrer le collective ownership avec les bonnes et les mauvaises pratiques ainsi que les différentes postures et situations fréquemment rencontrées .
Speakers : Peter Onneby, Consultant Anis Chaabani, Coach Agile et Craftsmanship Laurent Seng, Product Owner / Coach Agile Franck Cussac, Data Engineer
Notes
L’idée du Mob programing est de faire travailler toute l’équipe sur le même sujet.
La présentation est une pièce de théâtre composée de 2 actes.
L’acte 1 résume les mauvaises pratiques :
- Mauvaise communication
- Malveillance des managers : Mode command and control qui n’aide pas à faire avancer les choses
- Les poses chacun à son tour
- Pas d’investissement du métier
Ces conditions ne sont pas favorables pour le travail en équipe.
L’acte 2 est autour de l’implémentation d’un US avec TDD. Les speakers ont montré l’importance de l’implication des métiers pour l’écriture des critères d’acceptante. Ensuite, l’implémentation a été faire en mob programming.
Suite à l’implémentation de la Us, le PO vient tester, et valide. Le PO pourrait également s’intéresser à la partie technique / GIT.
La CI est lancée après le push et déploiement sur les environnement de production.
Avantages de cette approche
- Pas besoin de réunion de suivie
- Partage des connaissances
- Qualité sans compromis
- Le PO est plus proche des équipes
- La propriété collective du code
- Pas de dépendances aux individus
- Lors des MOB, on peut partir pour travailler sur d’autres sujet, mais, la cellule de développeurs continue de travailler
- Pas de chiffres aujourd’hui sur l’efficacité du model, mais, plusieurs entreprises le font tels que Rakuten, OTTO, INNOQ, SVT…
- Le PO doit être toujours disponible quand on fait de l’agilité
Il faut prendre les devants pour tester ensuite faire des REX au management. Les développeurs sont responsables du code, donc, ils doivent innover et améliorer leurs process de développement.
Conférence Agilité : Maintenant, Orange Bank devient une Entreprise Agile
Abstract
Orange Bank fête son 2ème anniversaire, l’occasion pour l’agence de la transformation digitale & agile de faire son retour d’expérience sur les changements qu’elle accompagne. Planification trimestrielle commune, Obeya, Tribus, DevOps… découvrez les différentes escales du voyage vers l’Entreprise Agile.
Speakers : Laurent Dussault @lolo_deck, Coach DevOps & Agile Marina Sosniak et Delphine Le Gal, chargées de la transformation digitale et agile chez Orange Bank
Notes
REX de la transformation agile de Orange Bank, rapprochement entre Groupama et Orange. La DSI est composé de 150 personnes.
L’agence de la transformation est rattachée à la DSI est composé de 3 coachs agile et 2 internes. La mission principale de l’agence est de définir la raison d’être des équipes et de les accompagner dans leurs transformations agiles.
Cette agence se veut exemplaire, et partage sa devise :
Build the right thing and build it right
Initiatives
Vendredi acquis
- Retour d’expérience sur Agile, devops
- Sessions mensuelle ouverte
- Basé sur la volontariat
IT is SEXY
- Démystifier l’IT
- Immersion au sein du services DSI
- Format conférence avec des ateliers de DEV ..
Interactions
- Canal d’expression pour tous au sein de la DSI
- 19 ateliers
- 200 participations
- 80 actions
Cadre de référence du Mindset Agile
- Partager le cadre de travail et le même vocabulaire
- Plan de communication interne pour embarquer tous les collaborateurs
- Explication du rôle du PO
- Les interactions multi-équipes
Il faut avoir le go du CoDir & management pour réussir la transformation.
Accompagnement Co Dir :
- Mode Scrum
- Rôle de PO
- Rôle de scrum master
- Développement d’une relation de confiance
- Réaliser des demos fun
5 dysfonctionnement d’une équipe
L’agence a organisé plusieurs ateliers pour améliorer la qualité des relations dans les équipes et les managers :
- Manque de confiance
- Peur des conflits (harmonie artificielle)
- Manque d’engagement (ambiguïté)
- Responsabilité
- Résultats

Cet article détaille ces 5 points.
Transformations
L’agence a accompagné plusieurs équipes dans leurs transformations managériales et techniques.
OBEYA au niveau portefeuille projet à destination du Comex
- basée sur du management visuel
- Stratégie / idéation / cadrage / réalisation
- Les PO viennent pitcher leurs idées en mode stand up sans slides
Vers une organisation “Produit”
- Core team
- Chaine de valeur produits
- Les rôles de la tribu produit
Changement managerial :
- Donner le go pour le test. Se baser sur la démonstration
- Quick Wins
- faire des rétros inter/intra équipes
- Mise en place de vie-ma-vie entre les IT et les “clients” pour gagner en efficacité
Transformation DevOps
- Séminaire DSI
- Backlog
- Scrum & Management Visuel
- Définition des OKR (Objectif / key / result)
- Enlever le silo entre Dev & Ops
ROI
Le changement n’a pas été guidé par le ROI. L’objectif de la transformation est d’agir sur la culture, donc, le gain n’est pas vraiment mesurable en argent, mais, le changement de la boucle de feed back / TTM a été amélioré. Le gain financer n’était pas l’objectif principal.
Conférence Craft : Construire une communauté de dev dans une grande banque
Abstract
Les communautés de pratiques sont à la mode mais la mayonnaise ne prend pas toujours. Venez découvrir une communauté de développeurs qui vit depuis bientôt 2 ans dans une grande banque française.
Clément Rochas, Coach Agile @crochas Monica Sciortino, IT Manager, Natixis
Notes
Start with why ?
Volonté de la DSI de mettre l’accent sur
- Agilité
- DevOps
- Craftmanship
La communauté
- 3500 personnes à la DSI
- 100 équipes
- 25 coachs
Craft Academy :
- Réalisée pour les développeurs et animée par les développeurs
- Partager les éxpériences / méthodes / pratiques
- La devise : Learn - code - build
- Vitrine du Sotware Craftsmanship
- Ouvert à l’extérieur
- Espace de rencontre entre les différentes équipes
- créer un catalogue de Kata
- Partager les supports / méthodes …
- Coaching sur tous les aspects Craftmanship
- Toutes les semaines
Approche produit : Le produit Craft Academy
- Les coachs animent les sessions
- Indicateurs tels que le nombre de follower su Yammer, nombre de personnes qui assistent aux sessions
- Lancement lean startup
- Petit
- Public ciblés
- écouter les participants
- Les nouveaux arrivés participent à la création du vision produit
- création de poster / flyers …
- Communication sur les valeurs : il faut utiliser tous les outils de communication pour faire parler de l’Initiative
- Kata en mob programming
- Se baser sur un outil pour définir la liste des personnes qui veulent venir
- Espace bitbucket de Kata
- Coding Dojo
- Git par la pratique -> pas très bien accueilli
- Code smells -> pas très bien accueilli
- Plus que 20 évènements par an
- Il faut aller voir les gens, à part la communication officielle
- Pas de Skype
- Motivation des gens en régions (NY, London, HK, Porto …) (Porto : Centre de développement avec la majorité des dev natixis sont faits).
- Il faut bien choisir le lieu ou faire les évènements
- Il faut avoir un leader qui met de l’énergie et enthousiasme
- Il faut trouver le bon vecteur de communication
- Penser à faire des présentations pour les managers / business. Il y a des méthodes et pratiques pour expliquer tous les aspects du Craftsmanship
- Il faut aborder avec les managers les aspects de qualité / tests / maintenabilité
Idées de Kata
Voici une liste des Kata proposés :
Les sujets
- Menu par année
- TDD
- Legacy Code
- BDD
- Design
- Source code management
- Product Management
- Faire des épisodes rythmés
- BDD session très intéressante + un vrai résultat
- DDD & architecture hexagonale sont des sujets importants
- Généralement 10 personnes présentes
Effets de l’Academy
- Développeurs motivés
- Sessions avancées entre DEV & métier
- Pour les managers, il faut se dire qu’il faut aller à la Craft Academy pour évoluer le niveau des développeurs.
Conseils
- RDV fixe
- Mob Programming
- Elargir au métier avec du BDD/DDD
Mot du fin du Head of Natixis Digital Factory
Le craft c’est l’humain au coeur du code !
Conférence Cloud : Cloud Native Apps
Abstract
Toute la mouvance “Cloud Native” impacte fortement la conception d’application, et pour cause : le but est de rendre celles-ci scalables, déployables automatiquement et résilientes by design. Alors comment concevoir de telles applications ? Est-ce que le temps des API REST ne serait pas dépassé ? Comment bénéficier des fonctionnalités d’un orchestrateur sous-jacent et de toutes les briques associées pour n’avoir que le minimum vital à faire pour déployer une nouvelle application from scratch ?
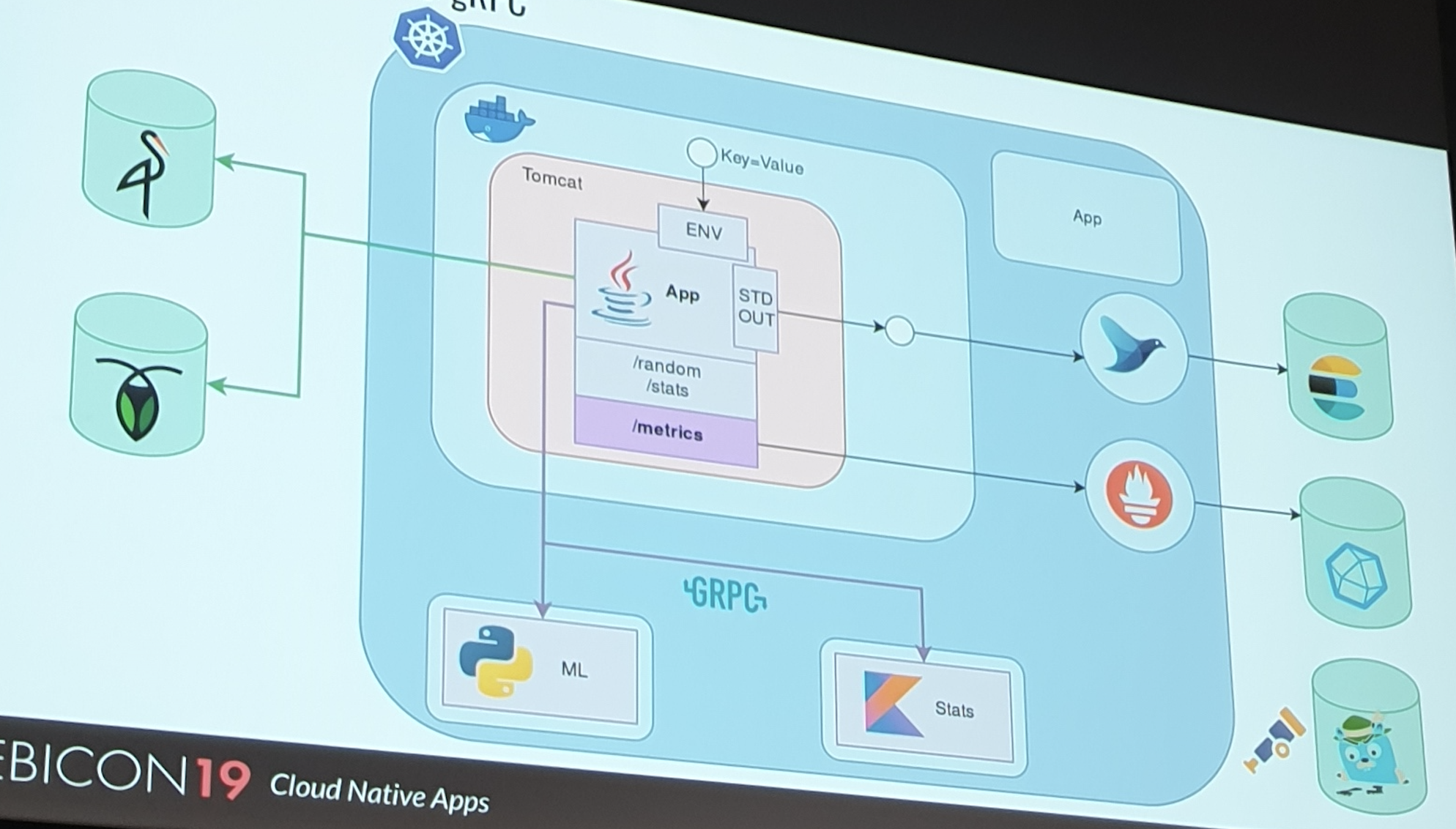
Nous tâcherons, en 30 minutes, de faire le tour de ces questions. Nous parlerons design d’APIs, gRPC, messaging, logging, monitoring aussi bien technique que business, 12 factor, et encore bien d’autres choses.
Alexis Chotard @Horgix, SRE
Notes
Imaginer une application x-blagues
- API
- Chercher des blagues
- Un ML pour prévoir si les blagues auront du succès
- Des statistiques
Exemple de stack technique
- VM
- Systemd qui gère le system
- Serveur tomcat & base Sql lite
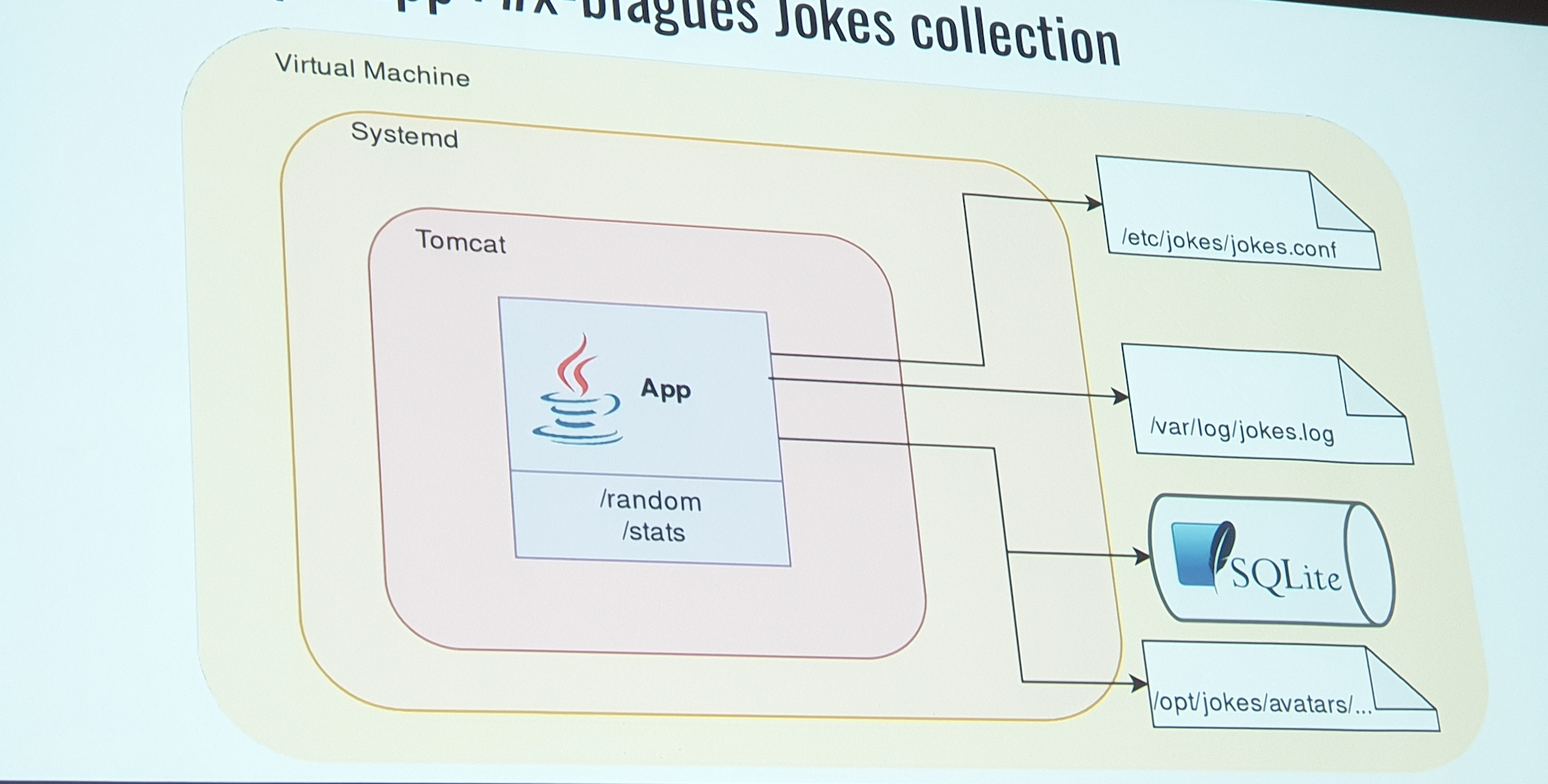
Les problématiques :
- Pas de scalabilité horizontale
- Pas de résilience
- Monitoring via
tail log - Performance limitée
- Long TTM
- Beaucoup de maintenance
Cloud
Les applications Cloud native :
- scalable
- résiliente
- observable
- performante
- TTM
- facilité des déploiements
- Peu de maintenance
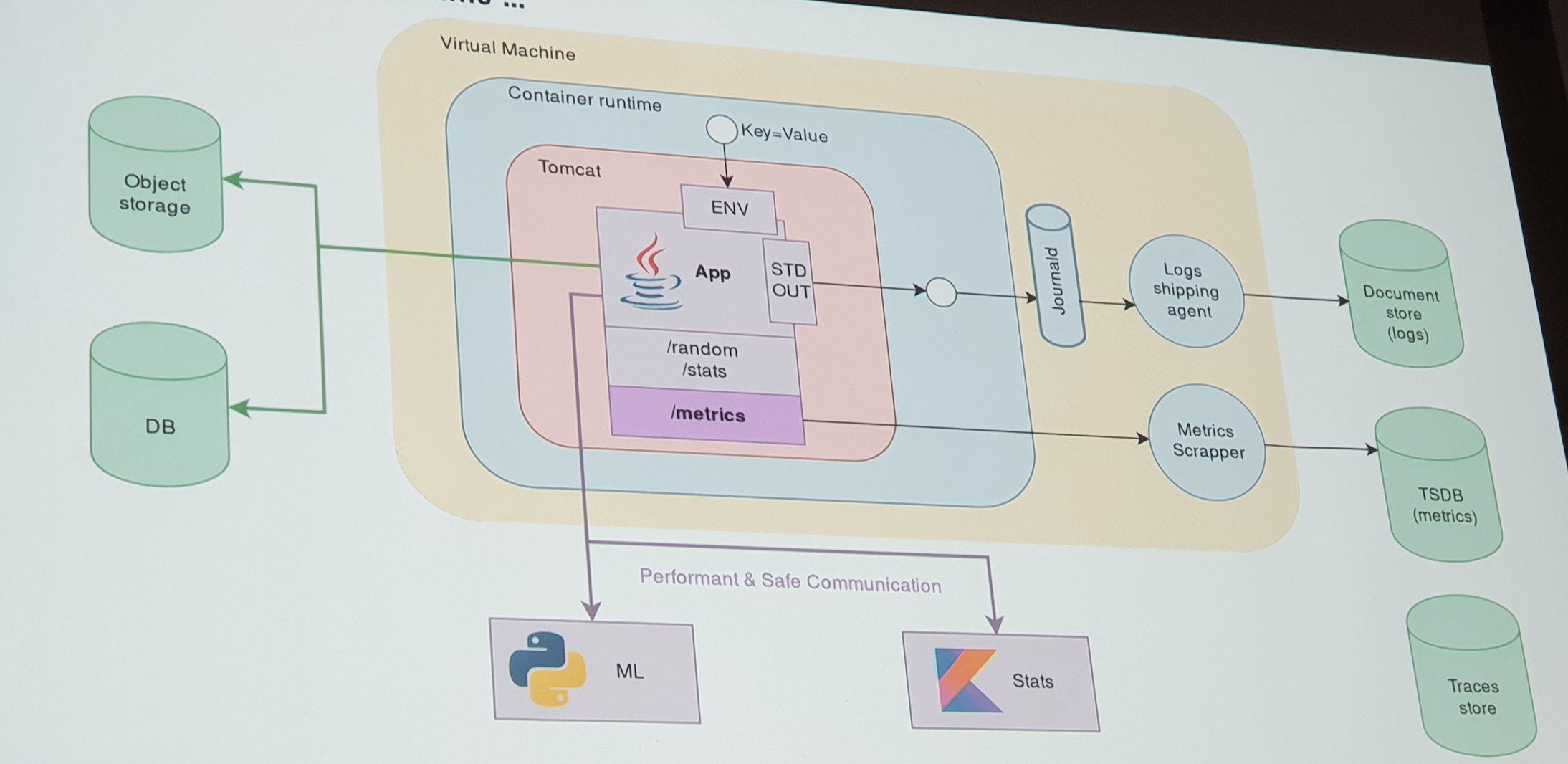
Comment y arriver ?
On s’inspire des fournisseurs de PaaS pour définir les patterns et concepts à mettre en place.
- Eviter le couplage avec les systèmes sous-jacents (par exemple les fichiers de log)
- Mettre sur STDOUT
- Mettre des variables d’environnement en mode Key-value pour configurer les lancement
- Déléguer la gestion des états
- Pour la DB, on peut penser à un object storage
- Mettre les DB en tant que ressource externe à requêter via appel réseau
- Utiliser les bonne technologies qui répondent aux besoins
- Utiliser Python pour la prédiction par exemple
- Faire des services à part pour les stats (Kotlin par exemple)
- Communiquer entre les différents éléments avec le protocole qui convient
- Rendre l’instance plus observable depuis l’extérieur
- Faire un parser de log (penser dès le dev à faire des formats simple à parser)
- Utiliser des documents storage & logs
- Gérer les métrics (times series)
- Traces store : suivre le reqêtes à travers des ids uniques pour pouvoir investiguer / debugger
- Automatiser tout : build, deploy, scale, react …
- Utiliser des conteneurs
- Etre indépendant de ce qui fait tourner l’application
- Orchestrateur qui fait abstraction au pull des machines
La CNCF fait des projets avec tous ces patterns.
Technos
- Prometius pour récupérer les métiques
- Open telemetrics
- gRPC : proto sur du RPC
Take away
- Eviter de se baser les technologies, et se focaliser sur les patterns et contraintes de l’application
- Provide the best application with the least effort
Fast Track Craft : 24 nuances de tests
Abstract
Tests unitaires, tests d’intégration, tests de performance, tests d’acceptation. Toutes ces nuances sont aujourd’hui bien connues et (nous l’espérons) de plus en plus souvent appliquées. Et si l’on poussait le bouchon jusqu’au bout, en se (sou)mettant en danger ? Testons (aussi) en production !
Pablo, CTO
Notes
Le speaker a pris l’exemple de l’échec du déploiement de la nouvelle version de MarioKart de Nintendo. Il y a un bug qui a du passer entre les mailles des filets des tests.
Il y a plusieurs types de test. Les tests les plus connus sont souvent les tests pre-prod. Mais, il existe aussi des tests en production.

Les risques des tests en prod :
- Tester en prod c’est faire un test en prod
- Il faut limiter l’effet Domino (plan de contingence)
- Les pires problèmes
- fuite de données
- corruption de données
- risque sur le chiffre d’affaire
REX
- my TF1
- 2 phases
- Beta testing sur une liste fermée d’users
- S’outiller pour le suivi des crash / note sur le store
- Oui SNCF
- Une partie des users seront redirigés vers la nouvelle plateforme en prod
- test par des robots
- Suez
- Stress test en production
- N26
- Bug Bounty
- Test de prod ultime
Conférence UX : Follow the UX Flow!
Abstract
“Tu es là parce que tu as un savoir, un savoir que tu ne t’expliques pas mais qui t’habite, un savoir que tu as ressenti toute ta vie. Tu sais que le monde ne tourne pas rond sans comprendre pourquoi, mais tu le sais, comme un implant dans ton esprit, de quoi te rendre malade. C’est ce sentiment qui t’as amené jusqu’à moi, sais-tu exactement de quoi je parle?”
“De l’UX ?”
“L’UX est universelle, elle est omniprésente, elle est avec nous ici, en ce moment même. Tu la vois chaque fois que tu regardes ton smartphone ou lorsque tu allumes ton ordinateur. Tu ressens sa présence lorsque tu vas au travail, quand tu vas au cinéma ou quand tu paies tes factures. Elle est le monde qu’on superpose à ton regard pour t’aider à voir ce dont tu as réellement besoin. “
Morpheus Matrix… ou presque !
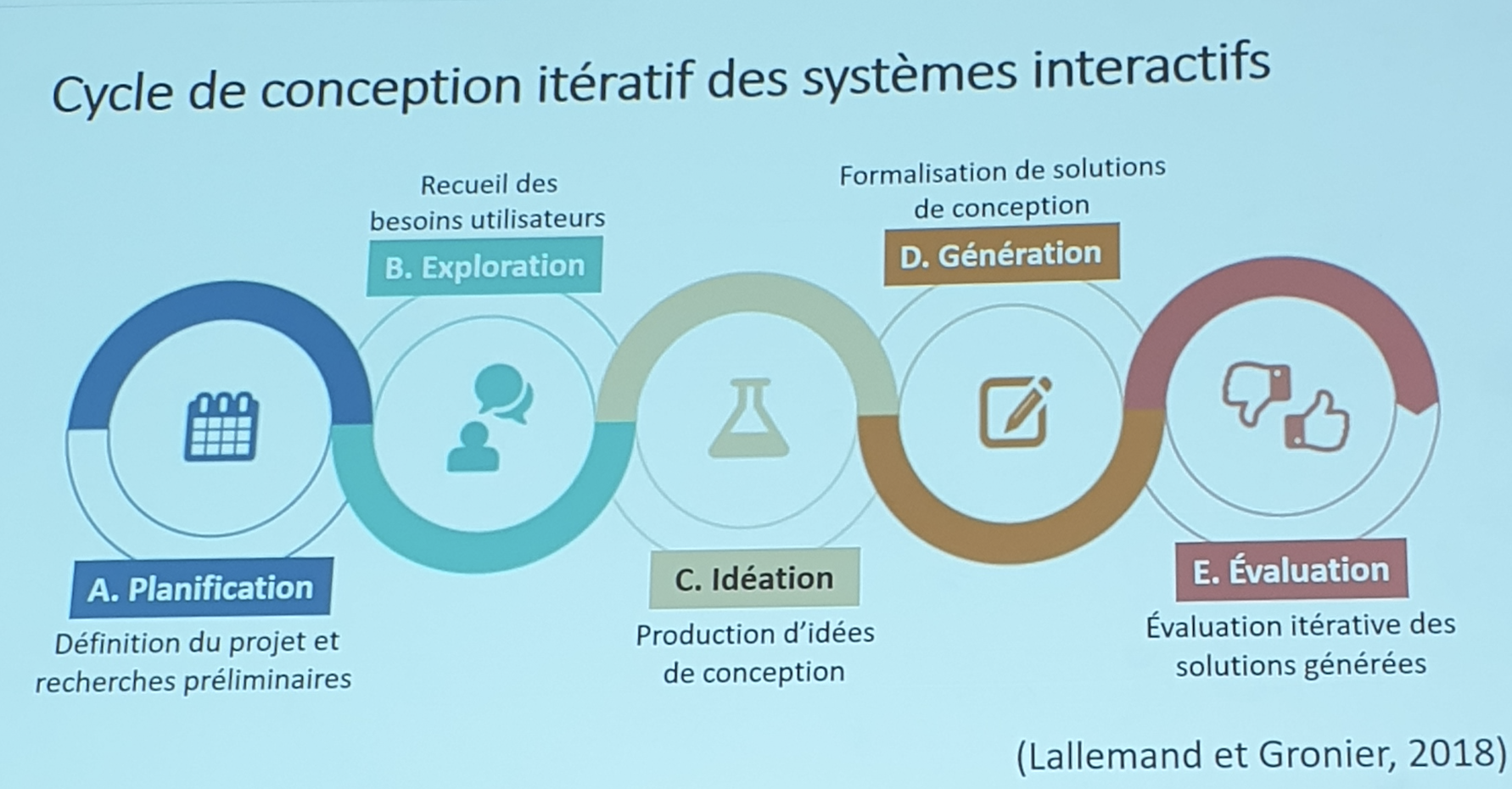
Vous l’aurez compris, nous allons parler d’UX Design. Je vous propose d’explorer le processus UX dans son intégralité, de suivre toutes les étapes qui permettent de construire une bonne UX et de voir l’impact que celle ci peut avoir sur un produit. Pour cela, nous passerons par les 5 étapes suivantes :
- La planification
- L’ exploration
- L’ idéation
- La génération
- L’ évaluation
A l’issue de ces étapes, le processus UX n’aura plus de secret pour vous !
David Attali @A_datta_D, Directeur Artistique
Notes
Le but de la présentation est d’expliquer le Workflow UX.
Cycle conception
Planification
- Analyse du brief clients
- Éclaircir les user qui vont l’Utiliser
- Qui sont -ils ? contexte ? différent topologies ? scénarios ?
- Motivations ? freins ?
- Faire des entretiens
- recherche secondaires / études / publications
- Le produit
- Existe déjà ? les contraintes ? comment l’utiliser ? Difficultés ?
- Pourquoi le problème existe ?
- Entretiens avec les parties prenantes
- Analyse des logs
- L’entreprise
- Identifier les parties prenantes
- Business Model/Histoire des produits
- KPI ?
- Éclaircir les user qui vont l’Utiliser
- Analyse concurrentielle
- Benchmark de la concurrence
- Solutions équivalentes ?
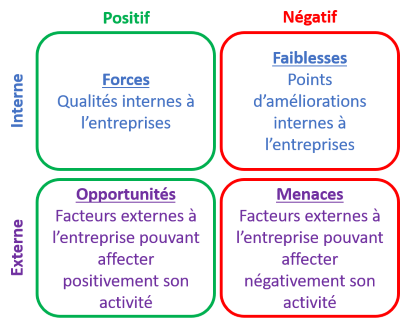
- Swot
- Permet de diagnostiquer les options stratégiques
- Formulation
- C’est obligatoire pour
- permet de juger ce qu’on produit
- On risque de créer un produit qui ,ne sera jamais utilisé
- Répondre précisément aux besoins users
- Exemple de formulation :
Entreprisecherche aobjectif. Aujourd’hui le problème estpoints de blocage, menaces, faiblesses.
Exploration
- User Research
- On n’est pas l’utilisateur du projet
- Définir un Persona
- Apporter des données au processus de design
- Prendre des décisions qui ont un sens
- Comprendre les utilisateurs
- questionnaires avec des questions simples
- entretiens avec des users
- Faire converger les points de vue
- Donner un sens au projet : pourquoi on fait les choses ? pour qui on fait les choses ?
- Etude qualitative
- Analyser pour comprendre
- Quels sont les blocages ?
- Psychologies
- Etude quantitative
- KPI & chiffre
- Synthèse
- identifier les cas extrêmes
- catégoriser les résultats
- Création des Affinity Map pour classer les données des users par critères
- Persona
- personnage fictif qui représente un groupes d’utilisateur
- il est basé sur le User Research
- Facilite l’affichage et partage
- 3 Persona idéalement (4 max)
- Pas de proto persona (un persona créé par l’équipe projet, sans consulter les users)

Idéation
- Aboutir a une vision
- Générer des idées en ayant un peu de recul
- Détourner les usages pour développer la créativité de l’idée
- Mind mapping
- Stimuler la création / libérer la créativité
- travail collaboratif
- Idée poussée
Personnalité et valeur de produit
- Définition d’une première version du produit
- Le contraire
- Miroir des contraires
- Evaluer les idées à travers des matrices de critères en mettant des notes
Génération
- Créer un produit optimal pour l’utilisation des users
- maquettes numériques
- maquette papier
- Le client doit dire si cela devrait répondre à ses besoins
- Enjeux
- Business
- Techniques
- Utilisateurs : Le feedback des utilisateurs est important
Evaluation
- Test users
- Pair review
- Questionnaires
- A/B testing
On faire des tests dans le cas d’un usage réel : compréhension / attraction / accessibilité / frustration / préférences …
Tout peut être testée :
- idée
- scénario d’usage
- tester le plus tôt et régulièrement
Evaluation experte
- Critères ergonomiques de Bastien et Scapin
- Feedback immédiat
- Il faut tout le temps communiquer avec les utilisateurs
Conférence Agilité : Scrum@Scale Demystified
Abstract
Venez découvrir Scrum@Scale, le framework de la Scrum Alliance et de Jeff Sutherland pour passer Scrum à l’échelle. Décrit dans un guide de 20 pages, ce framework semble simple mais est plus subtil et complexe qu’on ne le pense. En plus de comprendre son intention et son fonctionnement, nous verrons les points forts mais aussi les faiblesses de ce framework et comment il se compare aux autres frameworks d’agilité à l’échelle du marché.
Olivier Marquet @omarquet, Coach Agile
Notes
Ils existent plusieurs frameworks d’agilité à l’échelle :
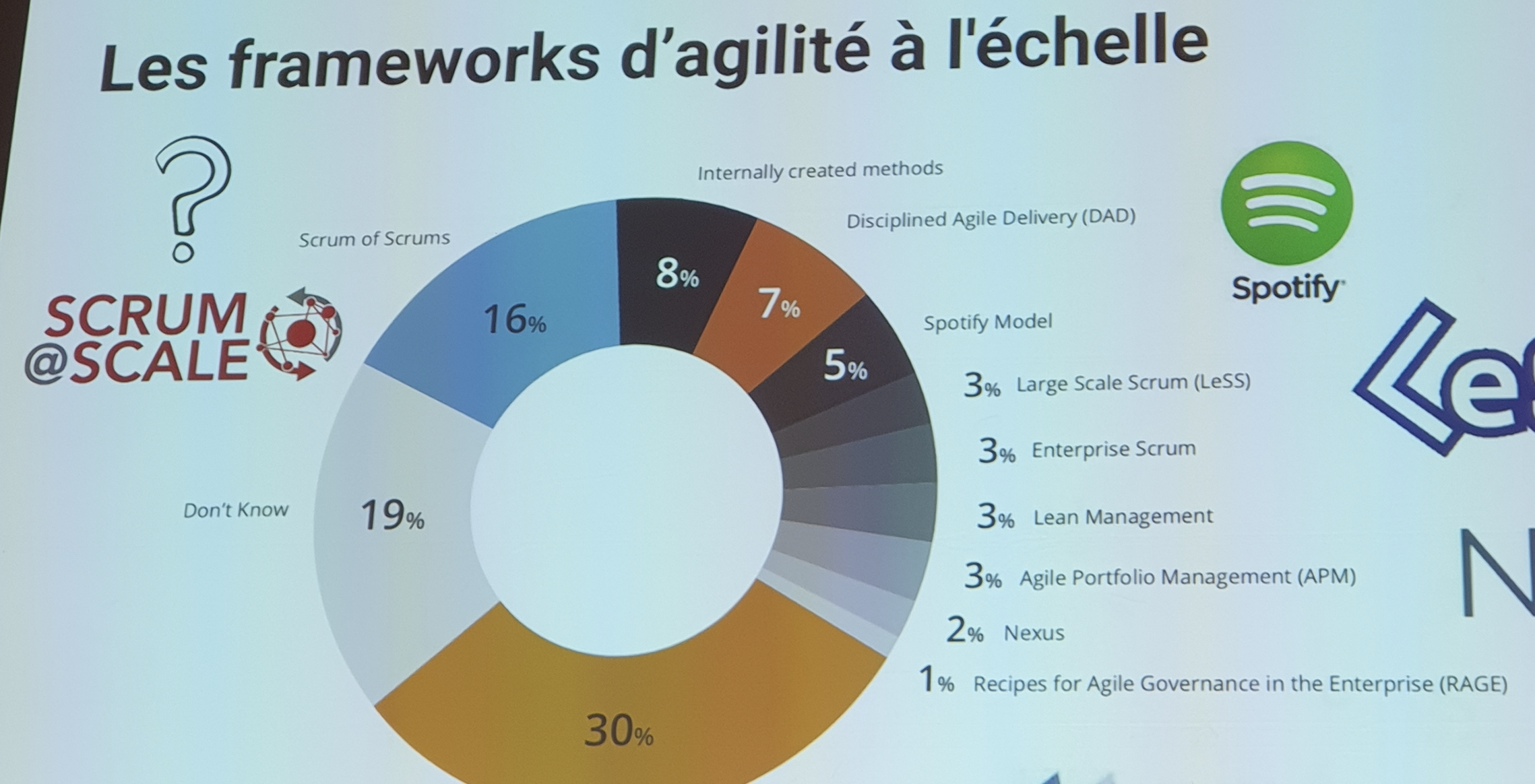
Scrum@scale est le framework d’agilité à l’échelle de la Scrum Alliance, qui est sorti en février 2018. L’objectif de ce framework est de coordonner de manière efficace des équipes qui fonctionnent déjà en Scrum
Bien comprendre le framework :
- compliqué et pas clair
- Pas de littérature sur le sujet
- Pas de Forum pour chercher de l’aide
Scrum of Scrum :
- Ensemble équipes Scrum
- Responsable d’un ensemble entité intégrée (IPL)
- Facilite la coordination
- Fonctionne comme une équipe scrum
- Dispose de toutes les compétences nécessaires
Scaled daily scrum
- Coordonner les équipes et supprimer les obstacle
- Un représentant de chaque équipe
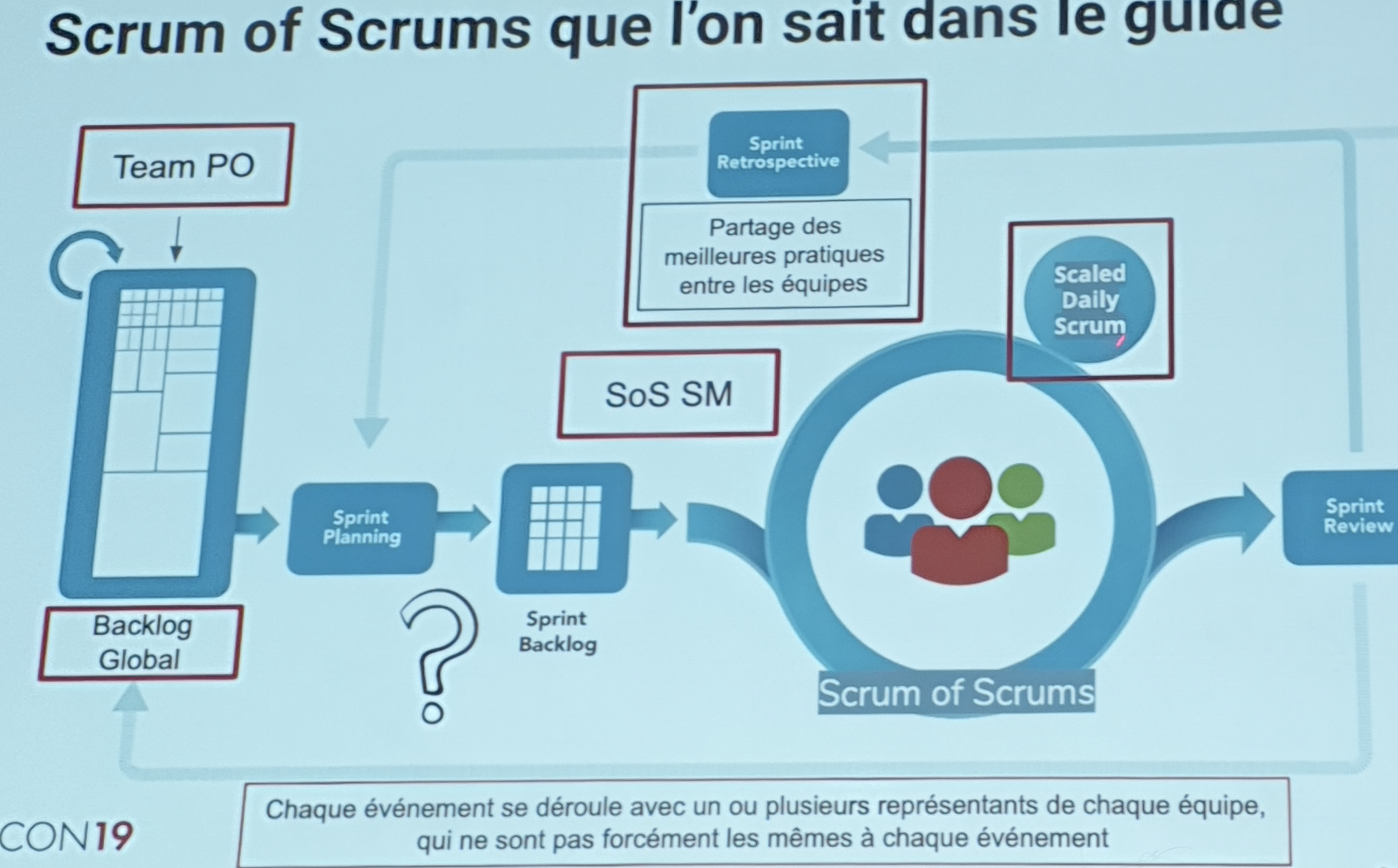
Les flous :
- SoS une équipe ou ensemble d’équipes ?
- SM de l’équipe PO ?
- Le meta scrum
- A quoi ressemble de scrum de l’équipe des PO ?
- La retro du SoS ?
Les composants
Scrum@Scale est formé de composant permettant à une organisation de personnaliser sa stratégie de transformation et sa mise en oeuvre.
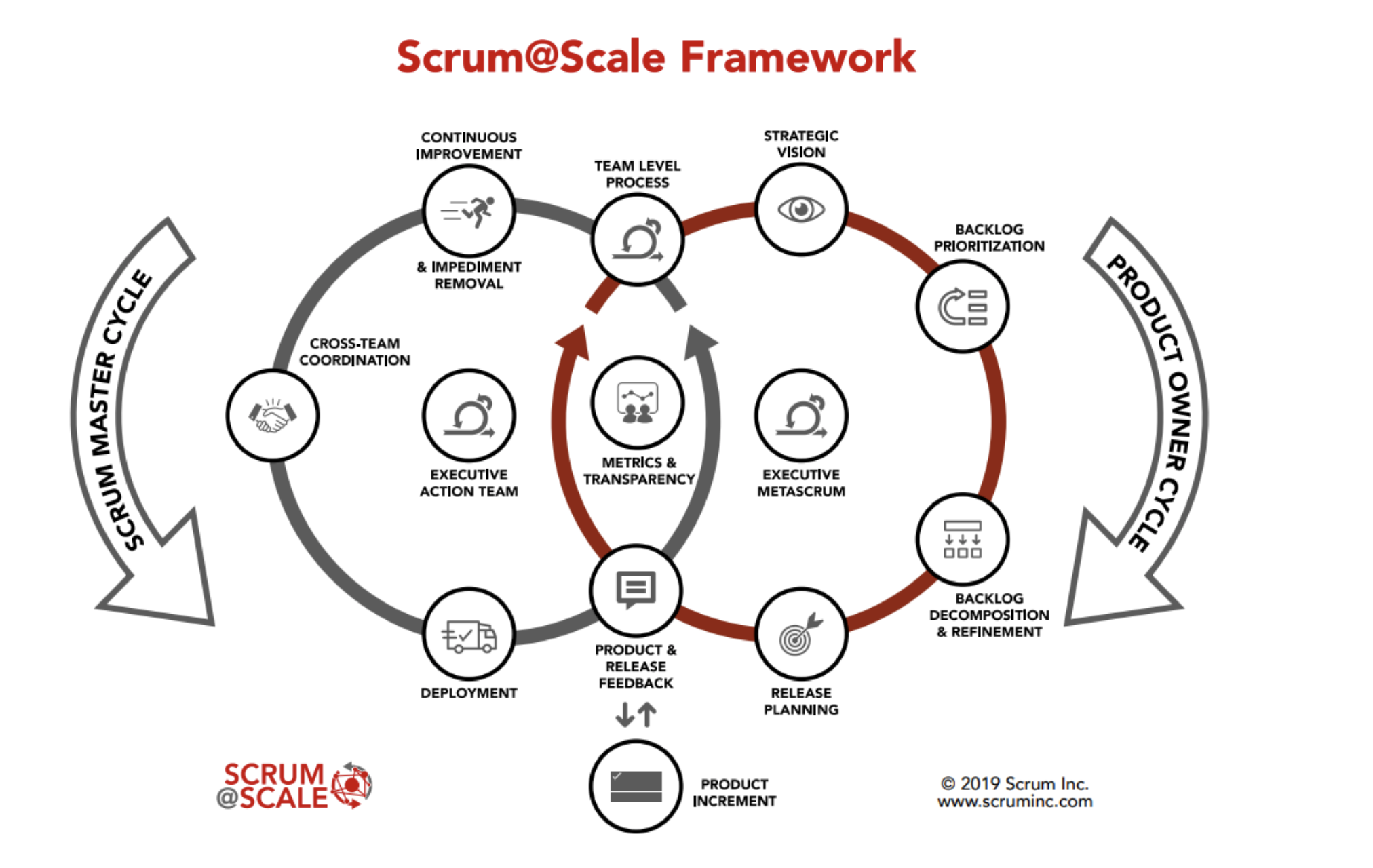
Take away
- difficile et contraignant dans certaines parties
- Approche composant qui permet d’adapter le framework
- Framework de niche
- Pas d’entreprise qui utilise le scrum@Scale
- Retenir la partie composant et réutiliser pour piloter les transformations
- Concurrence entre scrum.org & scrum alliance (framework LeSS)